Thank you to all who attended my seminar today. As promised, I am going to provide the code that I used to query the data underlying the Constitute site.
To start, you will need to know how to write a SPARQL query. There are good resources online to teach you how to write such queries (see here or here). Once you know a bit about writing SPARQL queries, you can test out your skills on the data underlying the Constitute site. Just copy and paste your queries here. To get you started, here are the two queries that I used in my seminar:
Query 1:
PREFIX ontology:<http://tata.csres.utexas.edu:8080/constitute/ontology/>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
SELECT ?const ?country ?year
WHERE {
?const ontology:isConstitutionOf ?country .
?const ontology:yearEnacted ?year .
}
Query 2:
PREFIX ontology:<http://tata.csres.utexas.edu:8080/constitute/ontology/>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
SELECT ?const ?country ?year ?region ?sectionType ?sectionText ?childType ?childText
WHERE {
?const ontology:isConstitutionOf ?country .
?const ontology:yearEnacted ?year .
?section ontology:isSectionOf ?const .
?country ontology:isInGroup ?region .
?section ontology:hasTopic ontology:env .
?section ontology:rowType ?sectionType .
OPTIONAL {?section ontology:text ?sectionText}
OPTIONAL {?childSection ontology:parent ?section . ?childSection ontology:text ?childText}
OPTIONAL {?childSection ontology:parent ?section . ?childSection ontology:rowType ?childType}
}
Notice the “topic” line in the second query (?section ontology:hasTopic ontology:env .). The env part of that line is the tag that we use to indicate provisions that deal with “Protection of environment”. You can explore the list of topics included on Constitute and their associated tags here.
The next step is to apply your querying knowledge using the SPARQL package in R. I will demonstrate how this is done by walking you through the creation of the Word Cloud that I discussed during my seminar (the code for the histogram is easier to understand and is below). First, query the SPARQL endpoint using R:
#Opens the Relevant Libraries
library(SPARQL)
#Defines URL for Endpoint
endpoint <- "http://tata.csres.utexas.edu:8080/openrdf-sesame/repositories/test"
#Defines the Query
query <- "PREFIX ontology:<http://tata.csres.utexas.edu:8080/constitute/ontology/>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
SELECT ?const ?country ?year ?region ?sectionType ?sectionText ?childType ?childText
WHERE {
?const ontology:isConstitutionOf ?country .
?const ontology:yearEnacted ?year .
?section ontology:isSectionOf ?const .
?country ontology:isInGroup ?region .
?section ontology:hasTopic ontology:env .
?section ontology:rowType ?sectionType .
OPTIONAL {?section ontology:text ?sectionText}
OPTIONAL {?childSection ontology:parent ?section . ?childSection ontology:text ?childText}
OPTIONAL {?childSection ontology:parent ?section . ?childSection ontology:rowType ?childType}
}"
#Queries the endpoint
sparql <- SPARQL(endpoint,query,ns=c('ontology','<http://tata.csres.utexas.edu:8080/constitute/ontology/>','const','<http://tata.csres.utexas.edu:8080/constitute/>'))
You now have a data table with the relevant textual data available to you in R under sparql$results. The second step is to organize that data into a corpus using the text mining package (tm, for short). Ultimately, I am only interested in rows in the data table that have text (i.e. the sectoinText and childText columns are not empty) and that are from constitutions written in the Americas or Africa, so I will filter the data along these lines in this step of the process. Here is the code:
#Opens the Relevant Libraries
library(tm)
library(SnowballC)
#Filters Out Correct Regions
data.Africa <- subset(sparql$results,sparql$results$region=="const:ontology/Africa")
data.Americas <- subset(sparql$results,sparql$results$region=="const:ontology/Americas")
#Extracts Section Text from Results and Removes Missing Values
sText.Africa <- subset(data.Africa,data.Africa$sectionText!='NA')
sText.Africa <- subset(sText.Africa$sectionText,sText.Africa$sectionType=="const:ontology/body")
sText.Americas <- subset(data.Americas,data.Americas$sectionText!='NA')
sText.Americas <- subset(sText.Americas$sectionText,sText.Americas$sectionType=="const:ontology/body")
#Extracts Child Section Text from Results and Removes Missing Values
cText.Africa <- subset(data.Africa,data.Africa$childText!='NA')
cText.Africa <- subset(cText.Africa$childText,cText.Africa$childType=="const:ontology/body")
cText.Americas <- subset(data.Americas,data.Americas$childText!='NA')
cText.Americas <- subset(cText.Americas$childText,cText.Americas$childType=="const:ontology/body")
#Appends Parent and Child Text Together
Text.Africa <- data.frame(c(sText.Africa,cText.Africa))
Text.Americas <- data.frame(c(sText.Americas,cText.Americas))
#Converts Data Frames to Corpora
corpus.Africa <- Corpus(VectorSource(Text.Africa))
corpus.Americas <- Corpus(VectorSource(Text.Americas))
Now that I have organized the relevant text into corpora, I need to clean those corpora by removing stop words (e.g. a, an and the), punctuation and numbers and stemming words. This is standard practice before analyzing text to prevent “the” from being the largest word in my word cloud and to make sure that “right” and “rights” are not counted separately. The tm package has all the tools to perform this cleaning. Here is the code:
#Makes All Characters Lower-Case
corpus.Africa <- tm_map(corpus.Africa,tolower)
corpus.Americas <- tm_map(corpus.Americas,tolower)
#Removes Punctuation
corpus.Africa <- tm_map(corpus.Africa,removePunctuation)
corpus.Americas <- tm_map(corpus.Americas,removePunctuation)
#Removes Numbers
corpus.Africa <- tm_map(corpus.Africa,removeNumbers)
corpus.Americas <- tm_map(corpus.Americas,removeNumbers)
#Removes Stopwords
corpus.Africa <- tm_map(corpus.Africa,removeWords,stopwords('english'))
corpus.Americas <- tm_map(corpus.Americas,removeWords,stopwords('english'))
#Stems Words
dict.corpus.Africa <- corpus.Africa
corpus.Africa <- tm_map(corpus.Africa,stemDocument)
corpus.Africa <- tm_map(corpus.Africa,stemCompletion,dictionary=dict.corpus.Africa)
dict.corpus.Americas <- corpus.Americas
corpus.Americas <- tm_map(corpus.Americas,stemDocument)
corpus.Americas <- tm_map(corpus.Americas,stemCompletion,dictionary=dict.corpus.Americas)
The last step is to analyze the cleaned text. I created a simple word cloud, but you could perform even more sophisticated text analysis techniques to the textual data on Constitute. I used the wordcloud package to accomplish this task. Here is the code I used to create the word clouds for my presentation:
#Opens the Relevant Libraries
library(wordcloud)
library(RColorBrewer)
library(lattice)
#Creates a PNG Document for Saving
png(file="WC_env.png", height = 7.5, width = 14, units = "in", res=600, antialias = "cleartype")
#Sets Layout
layout(matrix(c(1:2), byrow = TRUE, ncol = 2), widths = c(1,1), heights = c(1,1), respect = TRUE)
#Sets Overall Options
par(oma = c(0,0,5,0))
#Selects Colors
pal <- brewer.pal(8,"Greys")
pal <- pal[-(1:3)]
#Word Cloud for the Americas
wordcloud(corpus.Americas,scale=c(3,0.4),max.words=Inf,random.order=FALSE,rot.per=0.20,colors=pal)
#Creates Title for Americas Word Cloud
mtext("Americas",side=3,cex=1.25,line=4)
#Word Cloud for Africa
wordcloud(corpus.Africa,scale=c(3,0.4),max.words=Inf,random.order=FALSE,rot.per=0.20,colors=pal)
#Creates Title for African Word Cloud
mtext("Africa",side=3,cex=1.25,line=4)
#Creates an Overall Title for the Figure
mtext("Constitutional Provisions on the Environment",outer=TRUE,cex=2,font=2,line=1.5)
#Closes the Plot
dev.off()
Note that the plotting commands above are complicated by the fact that I wanted to combine two word clouds into the same image. Had I only wanted to create a single word cloud, say for Africa, and did not care much about the colors of the plot, the following commands would have sufficed:
#Opens the Relevant Libraries
library(wordcloud)
#Word Cloud for Africa
wordcloud(corpus.Africa,scale=c(3,0.4),max.words=Inf,random.order=FALSE,rot.per=0.20,colors=pal)
Anyway, here is the resulting word cloud:

With the commands above, you should be able to replicate the word clouds from my seminar. In addition, minor modifications to the commands above will allow you to describe the constitutional provisions on different topics or to compare the way that different regions address certain topics. One could even perform more advanced analyses of these texts with the SPARQL queries outlined above.
CODE FOR HISTOGRAM
#Opens the Relevant Libraries
library(SPARQL)
library(RColorBrewer)
#Defines URL for Endpoint
endpoint <- "http://tata.csres.utexas.edu:8080/openrdf-sesame/repositories/test"
#Defines the Query
query <- "PREFIX ontology:<http://tata.csres.utexas.edu:8080/constitute/ontology/>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
SELECT ?const ?country ?year
WHERE {
?const ontology:isConstitutionOf ?country .
?const ontology:yearEnacted ?year .
}"
#Makes the Query
sparql <- SPARQL(endpoint,query,ns=c('ontology','<http://tata.csres.utexas.edu:8080/constitute/ontology/>','const','<http://tata.csres.utexas.edu:8080/constitute/>'))
#Subsets Data
data.year <- data.frame(subset(sparql$results,select=c("const","year")))
#Drops Duplicate Observations
data.year <- unique(data.year)
#Makes Year Numeric
year <- as.numeric(data.year$year)
#Creates PNG Document for Saving
png(file="Histogram_Year.png")
#Selects Colors
pal <- brewer.pal(3,"Greys")
pal <- pal[-(1:2)]
#Histogram Command
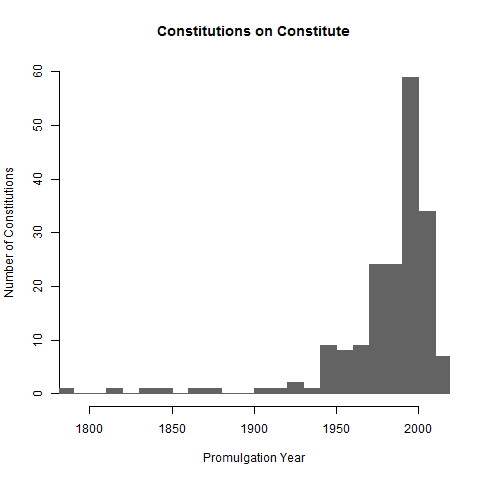
hist(year, breaks=21, col = pal, border = pal, xlab = "Promulgation Year", ylab = "Number of Constitutions", ylim = c(0,60), xlim = c(1790,2010), main = "Constitutions on Constitute")
#Closes the Plot
dev.off()
And here it is:

Like this:
Like Loading...